Deepseek And Love - How They're The same
페이지 정보
작성자 Maple 댓글 0건 조회 2회 작성일 25-03-06 15:56본문
Surprisingly, DeepSeek additionally launched smaller fashions educated by way of a process they name distillation. Let’s name it a revolution anyway! 4. Distillation is a lovely strategy, particularly for creating smaller, more efficient models. ElevenLabs for voiceovers: If you are creating movies or podcasts and need voiceovers, ElevenLabs is a good AI software that may show you how to with that. "The Chinese government attaches great importance to and legally protects data privacy and safety," ministry spokesperson Guo Jiakun mentioned at a regular briefing in Beijing. House has introduced the "No DeepSeek on Government Devices Act" to ban federal staff from using the DeepSeek app on government units, citing nationwide security considerations. Furthermore, citing solely the final pretraining run price is deceptive. This implies they're cheaper to run, but they can also run on lower-end hardware, which makes these particularly fascinating for a lot of researchers and tinkerers like me. These developments make DeepSeek-V2 a standout model for developers and researchers in search of each power and efficiency of their AI functions. The 67B Base mannequin demonstrates a qualitative leap in the capabilities of DeepSeek LLMs, displaying their proficiency throughout a wide range of purposes.
Instead, here distillation refers to instruction tremendous-tuning smaller LLMs, resembling Llama 8B and 70B and Qwen 2.5 fashions (0.5B to 32B), on an SFT dataset generated by larger LLMs. However, within the context of LLMs, distillation does not essentially observe the classical data distillation strategy used in deep learning. To analyze this, they utilized the identical pure RL strategy from DeepSeek-R1-Zero directly to Qwen-32B. The desk under compares the efficiency of those distilled models against other in style fashions, in addition to DeepSeek-R1-Zero and DeepSeek-R1. Specifically, these larger LLMs are DeepSeek-V3 and an intermediate checkpoint of DeepSeek-R1. Jailbreaking is a safety challenge for AI models, particularly LLMs. DeepSeek's success towards larger and extra established rivals has been described as "upending AI". While DeepSeek makes it look as though China has secured a strong foothold in the way forward for AI, it's premature to assert that DeepSeek’s success validates China’s innovation system as a complete. So, laws or govt action seems way more prone to have an effect on DeepSeek’s future as opposed to litigation. It could be interesting to explore the broader applicability of this optimization method and its impression on different domains. It’s additionally interesting to notice how properly these fashions carry out compared to o1 mini (I suspect o1-mini itself is likely to be a similarly distilled model of o1).
I strongly suspect that o1 leverages inference-time scaling, which helps clarify why it is costlier on a per-token foundation in comparison with DeepSeek-R1. This is able to help determine how a lot enchancment may be made, compared to pure RL and pure SFT, when RL is mixed with SFT. SFT (strategy 3) with inference-time scaling (approach 1). This is likely what OpenAI o1 is doing, except it’s most likely based mostly on a weaker base mannequin than DeepSeek-R1, which explains why DeepSeek-R1 performs so properly whereas remaining relatively cheap at inference time. 1. Inference-time scaling requires no extra coaching but increases inference costs, making large-scale deployment dearer as the quantity or users or query volume grows. SFT and inference-time scaling. This means that DeepSeek probably invested more closely within the training course of, whereas OpenAI may have relied extra on inference-time scaling for o1. Nvidia in an announcement referred to as DeepSeek "a wonderful AI advancement," calling it a "perfect example" of a concept known as take a look at time scaling. GPT-3 didn’t support lengthy context windows, but when for the moment we assume it did, then every additional token generated at a 100K context length would require 470 GB of memory reads, or round 140 ms of H100 time given the H100’s HBM bandwidth of 3.3 TB/s.
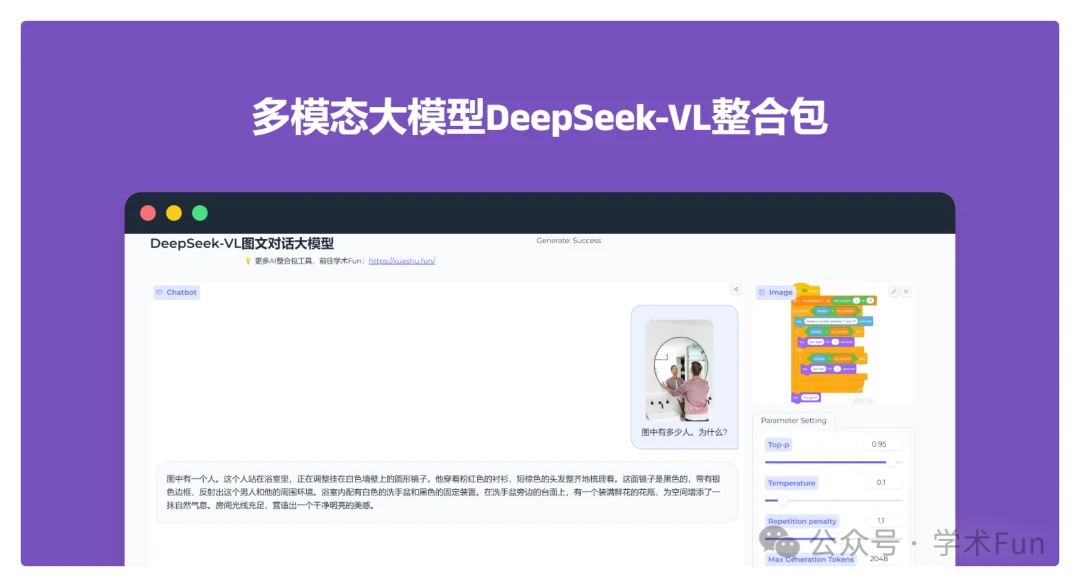 However, what stands out is that DeepSeek-R1 is extra environment friendly at inference time. Before wrapping up this section with a conclusion, there’s yet another attention-grabbing comparison price mentioning. This comparability offers some further insights into whether pure RL alone can induce reasoning capabilities in models much smaller than DeepSeek-R1-Zero. Claude 3.7 Sonnet is a well-rounded mannequin, excelling in graduate-degree reasoning (GPQA Diamond: 78.2% / 84.8%), multilingual Q&A (MMLU: 86.1%), and instruction following (IFEval: 93.2%), making it a strong alternative for enterprise and developer use instances. Its end-to-finish encryption ensures that delicate info stays protected, making it a most well-liked selection for businesses handling confidential data. The decentralized knowledge storage technique constructed into DeepSeek’s structure lowers the danger of knowledge breaches by stopping delicate information and personal chats from being stored in central databases. Specifically, users can leverage DeepSeek’s AI model via self-hosting, hosted variations from firms like Microsoft, or simply leverage a unique AI capability. 3. Supervised fantastic-tuning (SFT) plus RL, which led to DeepSeek-R1, DeepSeek’s flagship reasoning mannequin. However, the limitation is that distillation does not drive innovation or produce the next technology of reasoning fashions.
However, what stands out is that DeepSeek-R1 is extra environment friendly at inference time. Before wrapping up this section with a conclusion, there’s yet another attention-grabbing comparison price mentioning. This comparability offers some further insights into whether pure RL alone can induce reasoning capabilities in models much smaller than DeepSeek-R1-Zero. Claude 3.7 Sonnet is a well-rounded mannequin, excelling in graduate-degree reasoning (GPQA Diamond: 78.2% / 84.8%), multilingual Q&A (MMLU: 86.1%), and instruction following (IFEval: 93.2%), making it a strong alternative for enterprise and developer use instances. Its end-to-finish encryption ensures that delicate info stays protected, making it a most well-liked selection for businesses handling confidential data. The decentralized knowledge storage technique constructed into DeepSeek’s structure lowers the danger of knowledge breaches by stopping delicate information and personal chats from being stored in central databases. Specifically, users can leverage DeepSeek’s AI model via self-hosting, hosted variations from firms like Microsoft, or simply leverage a unique AI capability. 3. Supervised fantastic-tuning (SFT) plus RL, which led to DeepSeek-R1, DeepSeek’s flagship reasoning mannequin. However, the limitation is that distillation does not drive innovation or produce the next technology of reasoning fashions.
If you beloved this article so you would like to obtain more info about Free DeepSeek Ai Chat kindly visit our web site.
댓글목록
등록된 댓글이 없습니다.
