Ten Tips For Deepseek Success
페이지 정보
작성자 Lane Lange 댓글 0건 조회 3회 작성일 25-03-23 01:14본문
DeepSeek mentioned in late December that its giant language mannequin took solely two months and lower than $6 million to construct regardless of the U.S. Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., doing enterprise as DeepSeek, is a Chinese synthetic intelligence company that develops large language fashions (LLMs). In recent weeks, the emergence of China’s DeepSeek - a strong and cost-environment friendly open-supply language mannequin - has stirred considerable discourse amongst scholars and industry researchers. LMDeploy, a versatile and excessive-efficiency inference and serving framework tailor-made for large language fashions, now supports DeepSeek-V3. They have some modest technical advances, utilizing a distinctive type of multi-head latent consideration, numerous experts in a mixture-of-specialists, and their very own easy, environment friendly type of reinforcement learning (RL), which fits towards some people’s pondering in preferring rule-based rewards. Whether you’re new or wish to sharpen your skills, this book is a beneficial resource for studying JavaScript. "Grep by example" is an interactive information for studying the grep CLI, the text search device generally discovered on Linux programs.
 A helpful software in case you plan to run your AI-based software on Cloudflare Workers AI, where you can run these models on its world network using serverless GPUs, bringing AI purposes nearer to your customers. Get Deepseek free App. Chat on the go together with DeepSeek-V3 Your free all-in-one AI software. Start Now. Free Deepseek Online chat entry to DeepSeek-V3. She had just lately give up her stable job as a product supervisor at a significant tech firm to start her own business, and she now felt validated. On Monday, Gregory Zuckerman, a journalist with The Wall Street Journal, stated he had realized that Liang, who he had not heard of previously, wrote the preface for the Chinese version of a book he authored concerning the late American hedge fund manager Jim Simons. The Wall Street Journal reported on Thursday that US lawmakers were planning to introduce a authorities invoice to dam DeepSeek from authorities-owned units. 그래서, DeepSeek 팀은 이런 근본적인 문제들을 해결하기 위한 자기들만의 접근법, 전략을 개발하면서 혁신을 한층 가속화하기 시작합니다.
A helpful software in case you plan to run your AI-based software on Cloudflare Workers AI, where you can run these models on its world network using serverless GPUs, bringing AI purposes nearer to your customers. Get Deepseek free App. Chat on the go together with DeepSeek-V3 Your free all-in-one AI software. Start Now. Free Deepseek Online chat entry to DeepSeek-V3. She had just lately give up her stable job as a product supervisor at a significant tech firm to start her own business, and she now felt validated. On Monday, Gregory Zuckerman, a journalist with The Wall Street Journal, stated he had realized that Liang, who he had not heard of previously, wrote the preface for the Chinese version of a book he authored concerning the late American hedge fund manager Jim Simons. The Wall Street Journal reported on Thursday that US lawmakers were planning to introduce a authorities invoice to dam DeepSeek from authorities-owned units. 그래서, DeepSeek 팀은 이런 근본적인 문제들을 해결하기 위한 자기들만의 접근법, 전략을 개발하면서 혁신을 한층 가속화하기 시작합니다.
Until a couple of weeks ago, few people in the Western world had heard of a small Chinese synthetic intelligence (AI) firm referred to as DeepSeek. The Chinese technological neighborhood could distinction the "selfless" open source strategy of DeepSeek with the western AI fashions, designed to solely "maximize earnings and inventory values." After all, OpenAI is mired in debates about its use of copyrighted supplies to practice its fashions and faces various lawsuits from authors and news organizations. If you’re utilizing externally hosted models or APIs, corresponding to those out there by the NVIDIA API Catalog or ElevenLabs TTS service, be mindful of API utilization credit score limits or different associated prices and limitations. NVIDIA Blueprints are reference workflows for agentic and generative AI use circumstances. Designed to look sharp at any measurement, these icons can be found for various platforms and frameworks including React, Vue, Flutter, and Elm. DeepSeek is offered on both iOS and Android platforms. 다시 DeepSeek 이야기로 돌아와서, DeepSeek 모델은 그 성능도 우수하지만 ‘가격도 상당히 저렴’한 편인, 꼭 한 번 살펴봐야 할 모델 중의 하나인데요.
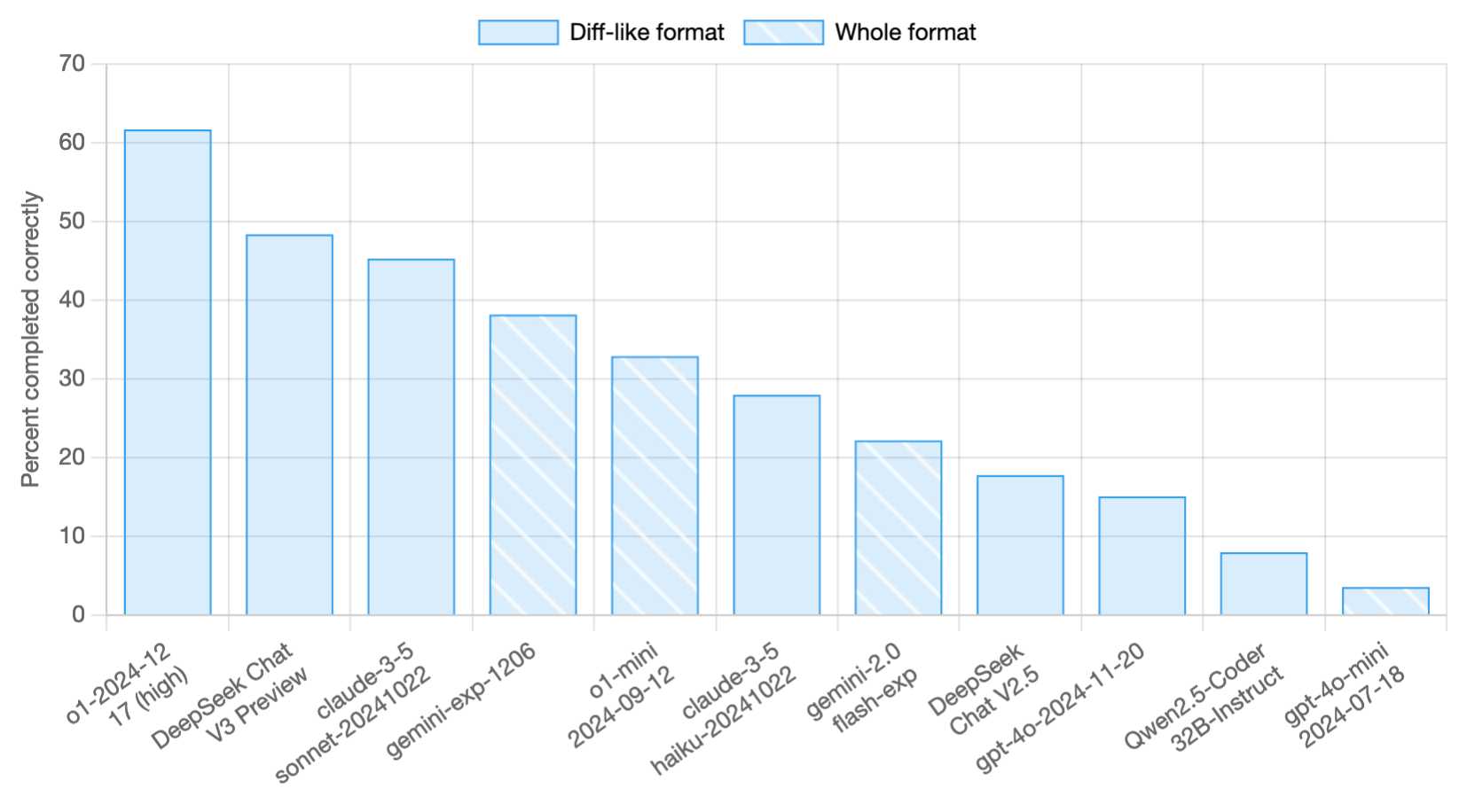 2023년 11월 2일부터 DeepSeek의 연이은 모델 출시가 시작되는데, 그 첫 타자는 DeepSeek Coder였습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. 또 한 가지 주목할 점은, DeepSeek의 소형 모델이 수많은 대형 언어모델보다 상당히 좋은 성능을 보여준다는 점입니다. 대부분의 오픈소스 비전-언어 모델이 ‘Instruction Tuning’에 집중하는 것과 달리, 시각-언어데이터를 활용해서 Pretraining (사전 훈련)에 더 많은 자원을 투입하고, 고해상도/저해상도 이미지를 처리하는 두 개의 비전 인코더를 사용하는 하이브리드 비전 인코더 (Hybrid Vision Encoder) 구조를 도입해서 성능과 효율성의 차별화를 꾀했습니다. 불과 두 달 만에, DeepSeek DeepSeek는 뭔가 새롭고 흥미로운 것을 들고 나오게 됩니다: 바로 2024년 1월, 고도화된 MoE (Mixture-of-Experts) 아키텍처를 앞세운 DeepSeekMoE와, 새로운 버전의 코딩 모델인 DeepSeek-Coder-v1.5 등 더욱 발전되었을 뿐 아니라 매우 효율적인 모델을 개발, 공개한 겁니다. 처음에는 Llama 2를 기반으로 다양한 벤치마크에서 주요 모델들을 고르게 앞서나가겠다는 목표로 모델을 개발, 개선하기 시작했습니다. 물론 허깅페이스에 올라와 있는 모델의 수가 전체적인 회사의 역량이나 모델의 수준에 대한 직접적인 지표가 될 수는 없겠지만, DeepSeek이라는 회사가 ‘무엇을 해야 하는가에 대한 어느 정도 명확한 그림을 가지고 빠르게 실험을 반복해 가면서 모델을 출시’하는구나 짐작할 수는 있습니다. 특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다. AI 학계와 업계를 선도하는 미국의 그늘에 가려 아주 큰 관심을 받지는 못하고 있는 것으로 보이지만, 분명한 것은 생성형 AI의 혁신에 중국도 강력한 연구와 스타트업 생태계를 바탕으로 그 역할을 계속해서 확대하고 있고, 특히 중국의 연구자, 개발자, 그리고 스타트업들은 ‘나름의’ 어려운 환경에도 불구하고, ‘모방하는 중국’이라는 통념에 도전하고 있다는 겁니다.
2023년 11월 2일부터 DeepSeek의 연이은 모델 출시가 시작되는데, 그 첫 타자는 DeepSeek Coder였습니다. 역시 중국의 스타트업인 이 DeepSeek의 기술 혁신은 실리콘 밸리에서도 주목을 받고 있습니다. 또 한 가지 주목할 점은, DeepSeek의 소형 모델이 수많은 대형 언어모델보다 상당히 좋은 성능을 보여준다는 점입니다. 대부분의 오픈소스 비전-언어 모델이 ‘Instruction Tuning’에 집중하는 것과 달리, 시각-언어데이터를 활용해서 Pretraining (사전 훈련)에 더 많은 자원을 투입하고, 고해상도/저해상도 이미지를 처리하는 두 개의 비전 인코더를 사용하는 하이브리드 비전 인코더 (Hybrid Vision Encoder) 구조를 도입해서 성능과 효율성의 차별화를 꾀했습니다. 불과 두 달 만에, DeepSeek DeepSeek는 뭔가 새롭고 흥미로운 것을 들고 나오게 됩니다: 바로 2024년 1월, 고도화된 MoE (Mixture-of-Experts) 아키텍처를 앞세운 DeepSeekMoE와, 새로운 버전의 코딩 모델인 DeepSeek-Coder-v1.5 등 더욱 발전되었을 뿐 아니라 매우 효율적인 모델을 개발, 공개한 겁니다. 처음에는 Llama 2를 기반으로 다양한 벤치마크에서 주요 모델들을 고르게 앞서나가겠다는 목표로 모델을 개발, 개선하기 시작했습니다. 물론 허깅페이스에 올라와 있는 모델의 수가 전체적인 회사의 역량이나 모델의 수준에 대한 직접적인 지표가 될 수는 없겠지만, DeepSeek이라는 회사가 ‘무엇을 해야 하는가에 대한 어느 정도 명확한 그림을 가지고 빠르게 실험을 반복해 가면서 모델을 출시’하는구나 짐작할 수는 있습니다. 특히 DeepSeek-Coder-V2 모델은 코딩 분야에서 최고의 성능과 비용 경쟁력으로 개발자들의 주목을 받고 있습니다. AI 학계와 업계를 선도하는 미국의 그늘에 가려 아주 큰 관심을 받지는 못하고 있는 것으로 보이지만, 분명한 것은 생성형 AI의 혁신에 중국도 강력한 연구와 스타트업 생태계를 바탕으로 그 역할을 계속해서 확대하고 있고, 특히 중국의 연구자, 개발자, 그리고 스타트업들은 ‘나름의’ 어려운 환경에도 불구하고, ‘모방하는 중국’이라는 통념에 도전하고 있다는 겁니다.
- 이전글What To Count on From Your Conveyancing Solicitor 25.03.23
- 다음글1982 - The Year In Music 25.03.23
댓글목록
등록된 댓글이 없습니다.
